This post is about laying some foundations, to help make the Pellet project a success. I’ll talk about prototyping APIs and testing ideas out, to make sure the end result is pleasant to use; integration and load testing, to make sure the project is fast and stable; and finally, I’ll finish up with some work on a “buffer pool” that I’ve been experimenting with, which is a more specific kind of performance improvement.
You can find the project, and all the code referenced below, at https://github.com/lopcode/Pellet/.
As an aside, before we get started with API basics, I recently discovered that there’s an updated HTTP 1.1 spec! RFC 72301, and a few after it, are a new group of specs intended to consolidate 20+ years of errata and informal specs since RFC 26162 (from 1999 🙀). I’ll be following this group of specs from now on.
API Basics #
First, I’ve defined the concept of Connectors, which are entry points in to the application. Connectors are capable of talking a particular protocol (like HTTP), over a particular endpoint (hostname and port, in HTTP’s case).
An HTTP connector has a Router associated with it. An HTTP router describes routes (HTTP method, and path, like GET /v1/hello), which map to a route handler, which actually sends a response back to the requesting client. Routers can be shared between connectors if you so wish (for example, to expose the same routes on both HTTP and HTTPS ports).
It’s worth noting that everything is geared up for Kotlin’s Coroutines – which provide a really elegant and powerful foundation to build fundamentally asynchronous applications on.
As an example, here’s a Pellet server with one HTTP connector, listening on localhost:8082, with a router defining a single endpoint at GET /v1/hello, which responds with 204 No Content, and includes a “hello world” header:
fun main() = runBlocking {
val pellet = pelletServer {
httpConnector {
endpoint = PelletConnector.Endpoint(
hostname = "localhost",
port = 8082
)
router {
get("/v1/hello") {
HTTPRouteResponse.Builder()
.noContent()
.header("X-Hello", "World")
.build()
}
}
}
}
pellet.start().join()
}
These concepts remain flexible enough that Pellet could reasonably host other kinds of connectors all in one application. The reason for this flexibility is that I have HTTP 2 on my mind, and applications may want to expose a port for some form of debugging, or hosting both HTTP and GRPC routes.
A pet peeve of mine with existing frameworks is the insistence on only showing inline and lambda-based routes (which you should avoid for non-trivial applications). Pellet supports these thanks to the route handler interface, PelletHTTPRouteHandling, using Kotlin’s fun interface - here’s a class-based version of the same route:
private class HelloRouteHandler: PelletHTTPRouteHandling {
override suspend fun handle(
context: PelletHTTPRouteContext
): HTTPRouteResponse {
return HTTPRouteResponse.Builder()
.noContent()
.header("X-Hello", "World")
.build()
}
}
Which you would register similarly:
fun main() = runBlocking {
val helloRouteHandler = HelloRouteHandler()
val pellet = pelletServer {
httpConnector {
endpoint = PelletConnector.Endpoint(
hostname = "localhost",
port = 8082
)
router {
get("/v1/hello", helloRouteHandler)
}
}
}
pellet.start().join()
}
Integration testing #
At the start of the project, where the public API changes often as I test ideas out, it makes more sense to use integration tests to make sure that things are as they should be. Spending lots of time on unit testing in the prototyping phase has less utility, as you would need to change or even rewrite them frequently. There’s an argument to be had about test-driven development (TDD, or “test first”) being the one true path for software development, and I may well do that when the dust settles a little. I’ve done TTD a lot in the past, but at the moment, it doesn’t feel appropriate.
The first integration test that I’ve written starts up a full Pellet server, with a single HTTP connector, fires off 100k requests, and waits for them to all respond correctly – with any incorrect responses marking the test as a failure. It’s a simple way of making sure that changes haven’t broken something fundamental.
The test also measures the “requests per second” (RPS) that Pellet managed, which makes it a bit like a “load test”, which I’ll talk about next.
Load testing #
Performance is important to me for this project, but being the fastest isn’t. My gut feeling is that a server should be able to handle something in the range of 10k to 100k requests per second on a relatively fast laptop, and I want to make sure that remains the case as the project grows.
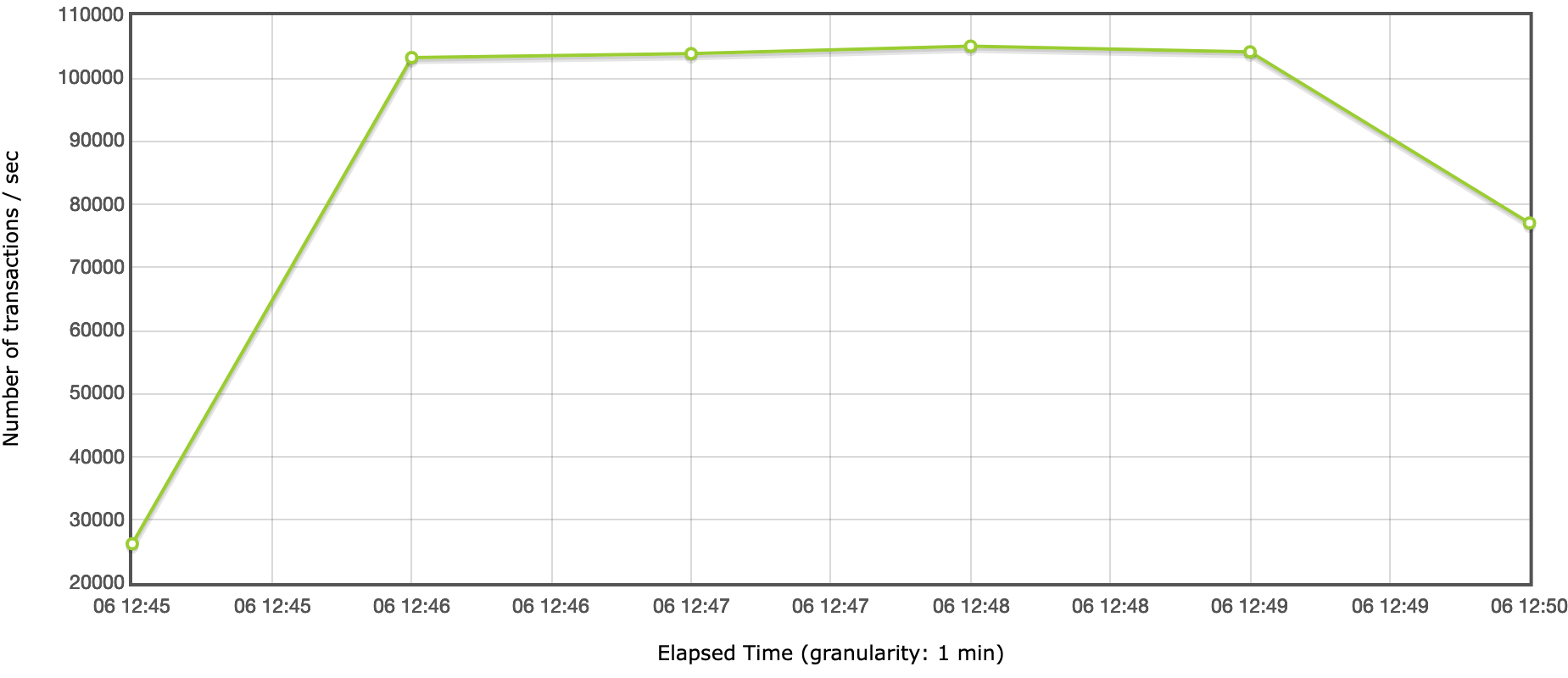
To that end, I’ve made a load testing suite using JMeter3, and a script to manage it. The load test runs for 5 minutes and attempts to make as many requests as possible, with any failures failing the entire test run. Here’s a graph of how Pellet does on my laptop at the moment, showing an RPS of around 103k (after the warmup, and before the cooldown):
I found that I wanted faster feedback about performance in day-to-day development, so I use a tool called hey4 which I can run for 10-20 seconds to get a feeling for whether a change did something particularly terrible. This actually produces very similar results to JMeter, which is promising:
🥕 carrot $ hey -z 10s http://localhost:8083/v1/hello
Summary:
Total: 10.0007 secs
Slowest: 0.0724 secs
Fastest: 0.0000 secs
Average: 0.0005 secs
Requests/sec: 101645.1329
...
In the future, I’d like to compare these results against other common libraries (like Jooby, and Ktor), just to make sure we’re in the same ballpark for the same classes of route handler. This likely includes both simple (like returning a 204), and IO-bound (like interacting with a database) handlers.
Buffer pool #
Finally, I’ve played around with the idea of a “buffer pool”. In games and performance-oriented software, it’s common to avoid making allocations every time you need them – especially in tight loops. Instead, you make a bunch of allocations up front (or one big allocation of a lot of memory, and slice it up when requested), then “recycle” these allocations instead of deallocating them with every iteration of the loop. In principle this sounds like a good idea, but the JVM operates on the assumption of garbage collection (GC) so the concept of “deallocating” something isn’t available to us. Many smart people have worked on JVM GC to make it fast, which is to say that you can’t be sure that allocating a lot of ByteBuffers repeatedly is bad for performance – unless you measure it, and find out that it is a definite problem.
To try the concept out, I implemented an incredibly simple “buffer pool” and made a thin wrapper for ByteBuffer imaginatively named PelletBuffer. A PelletBufferPooling implementation can then provide a buffer, and release it when requested:
interface PelletBufferPooling {
fun provide(): PelletBuffer
fun release(buffer: PelletBuffer)
}
Anywhere in the code where I previously called ByteBuffer.allocate, I instead asked the buffer pool to provide a buffer, making sure to release it when it’s not needed any more. The need to release at all is a bit of a pain – GC would usually take care of deallocating the buffer. If you didn’t release the buffer, the pool would retain it forever, and you’d cause a memory leak.
I played around with buffer pooling strategies, but everything I did seemed to harm performance (which pretty much confirmed my suspicions about GC), so in the end I’ve left the buffer pool in but made provide always allocate a new buffer without retaining a reference to it. Having the buffer pool implementation in there from the start is still quite useful, as it doesn’t harm the internal API, and offers a place to experiment to squeeze out some extra performance, if required. It’s worth noting that Netty uses the buffer pooling strategy for reducing allocations, but they also have a custom buffer implementation as well, which likely helps.
Conclusion #
In conclusion, I’ve made quite a lot of progress with Pellet over the winter break. I’m having loads of fun – it’s very satisfying to design an API exactly how you want it. I must admit I’m sometimes driven by the memory of working around frustrating framework APIs in my professional career, but my motivation is generally positive, and I’m pleased with how the API is shaping up.
It’s interesting prototyping without writing unit tests at the start – in the past I went through a phase of doing TDD for everything, so doing only integration tests feels like a worthy experiment. We’ll see how painful getting a unit test suite up to scratch is later, and whether I feel more comfortable starting afresh with TDD for implementations.
Footnotes #
-
RFC 7230 - https://datatracker.ietf.org/doc/html/rfc7230 ↩
-
RFC 2616 - https://datatracker.ietf.org/doc/html/rfc2616 ↩
-
JMeter - https://jmeter.apache.org/ ↩